| Previous | Contents |
You may start PhatVoice from the Windows Start Menu (normally Start / Programs / PhatVoice / PhatVoice). If you do not have a PhatNoise DMS on your system, you will receive the following alert:
If this occurs, simply click on the Ok button if you only want to test pronunciations, otherwise click on the Ok button and then exit PhatVoice, insert your DMS, and then restart PhatVoice.
Once PhatVoice starts, you will see the following screen:
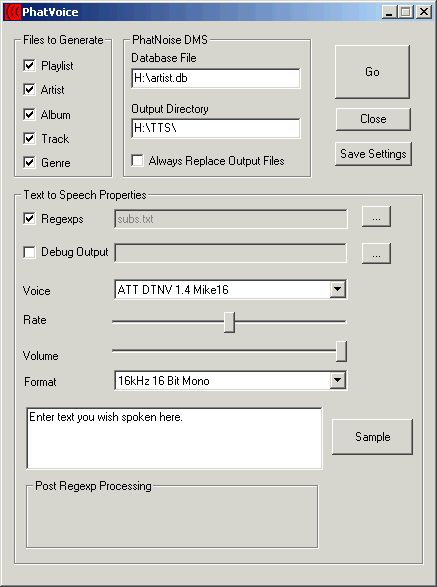
Each of the window areas is described below.
The major function buttons are located in the top right area of the window. They are:
The "Files to Generate" area controls which items to generate speech for. The following items are available:
The "PhatNoise DMS" area shows the path to the DMS files if a DMS was found when PhatVoice started, otherwise it will be blank. It contains the following items:
The PhatVoice developers have different opinions regarding the best way to accomplish the goal of replacing all output files. Some feel that it is better to delete all the .wav files in the TTS directory and let PhatVoice re-generate them all without checking the "Always Replace Output Files" box, while others feel that it is better to not delete the files manually and check the "Always Replace Output Files" box. There is a performance advantage to manually deleting the output files - this way, PhatVoice will only generate each speech item once. However, there may be cases where PhatVoice would generate a different filename or omit a speech item that PMM generates, which would then result in a missing announcement. If the "Always Replace Output Files" box is checked, PhatVoice will generate text for the selected speech items, but will generate it multiple times (for example, each time a specific artist appears on the DMS that artist's name will be re-generated). In essence, it is a time tradeoff - if you have the time, you should probably check "Always Replace Output Files" and let PhatVoice work for an extended period. |
The center area of the screen contains items related to pronunciation hints.
The PhatBox only supports a subset of the rates listed in this box. In particular, only 8KHz, 11KHz, 22KHz, and 44.1KHz (all in 16 bit mono) are supported on all PhatBox firmware revisions. |
The Microsoft Speech API does not do a good job of converting the sample rate of speech generated by the Natural Voices engine. You should make sure that the speech format is set to the native mode for the Natural Voices engine you are using (8KHz 16 Bit Mono for voices that do not end in 16 and 16KHz 16 bit Mono for voices ending in 16. If you are using a 16KHz Natural Voice, you will need to convert the speech files as described in Section 3.2 before the PhatBox can use them |
Additionally, if you click on the PhatVoice icon, you can select "About PhatVoice..." which will provide information about the version of PhatVoice in use as well as the copyright notice and additional information, as shown here:
Once you have selected your desired options as shown above, you should click on the Go button to generate the speech files. You will see each of the speech items as they are generated:
If any of the pronunciation hints cause the TTS engine to report an error (for example, if you specify a non-existent phoneme), PhatVoice will report the error, showing the particular speech item which caused the error. This will help you locate the error in your hints file.
The PhatNoise Music Manager sometimes re-generates speech files when used to eject the DMS. We recommend using the DMS Eject Utility (found in the Start / Programs / PhatNoise Music Manager / DMS Eject menu) to eject the DMS after generating speech with PhatVoice. |
The following is an advanced topic for users who have installed the 16KHz Natural Voices. Most users, including those who are using the Natural Voices supplied by PhatNoise on the PMM CD, don't need to worry about this. |
As mentioned above, if you have the 16KHz Natural Voices, the PhatBox cannot directly play the generated speech. The obvious solution of generating the speech at a rate the PhatBox supports doesn't work well, as the Microsoft Speech resampling introduces obvious artifacts in the speech. The solution is to use an out-board (additional) utility to convert the speech to a rate that the PhatBox will accept, while controlling conversion artifacts.
If you will be re-sampling your PhatVoice output, we suggest you override the default output location (normally the TTS directory of your DMS PHTDATA partition). Instead, put the output files on a scratch directory of your PC's hard disk and then have the resampling utility put its output files on the DMS, or copy them there later manually.
We give examples using two different utilities to do this. This does
not mean that these are the only utilities available, only that these
are two we have tried. Feel free to experiment with other utilities.
3.2.1 Processing with Yamp
Yamp is a shareware multi-purpose audio utility from Softuarium. It is available from:
http://www.softuarium.com/yamp.htm |
Use the WAV / resampler option to re-sample to 22 050 Hz,
16 bits / sample. We recommend checking the Two passes
checkbox.
3.2.2 Processing with SoX
SoX is a freeware utility for manipulating sound files. It is available from:
http://sox.sourceforge.net/ |
You will need a rather convoluted command line to have SoX process all of your files. As an example:
for %c in (*.wav) do sox "%c" -r 22050 new\\"%c" resample |
This will cause Sox to place the output files in a subdirectory called "new". The quotes around %c are required because the filenames can have embedded spaces and other special characters in them, and the double backslash is needed as SoX is a Unix-derived program where the backslash is a special character and not a directory delimiter.
You will find that once you generate speech for your DMS and listen to it, you'll find a number of cases where the text-to-speech engine mispronounces items. Using PhatVoice, you can customize the pronunciation of any speech generated for your DMS. This ranges from simple re-spelling of a word to generate a better pronunciation, all the way through a complete phonetic representation of a phrase, complete with additional hints for emphasis and pacing.
You can also rearrange text elements, such as changing "Sample
Album, The" into "The Sample Album" or generating
different speech such as changing "Demonstration Album - CD
1" into "Demonstration Album, Disc 1".
4.1 The pronunciation hints file
The pronunciation hints are entered into a plain text file which you can edit with an editor of your choice. A sample hints file called subs.txt is supplied with PhatVoice. You can either add your additional pronunciations to this file or create an entirely new file.
The syntax used for the hints file consists of regular
expressions embedded in Perl substitutions. If you don't
know what that means, don't panic - for most uses this is pretty
simple. We only mention this here so if you are interested in advanced
usage, you can locate additional information.
4.1.1 Substitutions and regular expressions
In all of these substitutions, case matters - The is not the same as the.
The basic substitution is performed with the s (substitute) command. If we wanted to change all instances of Yellow to Green, we would say:
s{Yellow}{Green}
|
in our pronunciation hints file. Note that the hint begins with the letter s (for "substitute"). The characters for "what we have" and "what we want" are each enclosed in braces ({ }).
However, there are two problems with this substitution. The first is that it will only be applied once per line, so if you had a playlist named Yellow - Yellow, you would end up with Green - Yellow. To correct this, we will make this substitution a global substitution by adding the letter g (for "global") to the end of the command. The second problem is that this will change all instances of Yellow. So if you had an item named "Yellowman" it would be changed to "Greenman". To avoid this, use the \b option at the end of the "what we have" string, like this:
s{Yellow\b}{Green}g
|
This will force the substitution to only apply where there is a word boundary (b for "boundary").
In other cases, you will have a large amount of text in the "what we have" side which you'd need to copy to the "what we want" side. Instead of re-typing the text, we can use the parenthesis grouping operators () to identify text we will then refer to in the "what we want" side as $1. For example:
s{(Einsturzende Neubauten)}{<voice required="name=Klara16">$1</voice>}
|
Instead of typing "Einsturzende Neubauten" over again, we just enclose it in parenthesis on the left side and refer to it as $1 on the right side.
You can use more advanced regular expressions to save you the effort of repeatedly coding a particular hint for slightly different instances. For example, to change the pronunciation of occurrences of a word boundary followed by 4 digits followed by a dash, use:
s{\b(\d\d\d\d)-}{<context id="date_year">$1</> - }g
|
When you load a hints file, either automatically as part of PhatVoice startup or via the Regexps file selection button, the file is checked for proper syntax. If there is an error in any of the hints, you will receive an error message such as this:
You may click Ok to ignore this error and continue loading the file, or Cancel to exit PhatVoice.
For additional information on debugging your hints, see Section 4.2.4.
4.1.2 The phonetic alphabet and other engine hints
Both the Microsoft Speech engine and the Natural Voices engine use the SAPI phonetic alphabet to express speech in phonemes. In cases where you can't generate the correct pronunciation using "creative mis-spelling" of a word, you will need to create a phonetic representation of the word or phrase. Table 4-1 shows the SAPI phonetic alphabet for US English. For other languages and dialects, consult either the Microsoft Speech or Natural Voices documentation.
In addition to phonetic pronunciation, there are a large number of other keywords you can use to control the engine. In the example in the previous section, we switched from the default voice to the Klara16 voice to pronounce a German phrase and then switched back to the default voice. Again, consult the Microsoft Speech or Natural Voices documentation for a complete list of the available keywords. If you install a version of PMM which includes Natural Voices, the manual is available in Windows at Start / Programs / AT&T Natural Voices 1.2 / Desktop / System Developer's Guide.
| Phoneme Symbol | Example | Transcription |
|---|---|---|
| aa | B ob | b aa b 1 |
| ae | b at | b ae t 1 |
| ah | b ut | b ah t 1 |
| ao | b ought | b ao t 1 |
| aw | d own | d aw n 1 |
| ax | about | ax b aw t 1 |
| ay | b ite | b ay t 1 |
| b | b et | b eh t 1 |
| ch | chur ch | ch er ch 1 |
| d | dig | d ih g 1 |
| dh | that | dh ae t 1 |
| eh | b et | b eh t 1 |
| er | b ird | b er d 1 |
| ey | b ait | b ey t 1 |
| f | fog | f ao g 1 |
| g | got | g aa t 1 |
| h | hot | h aa t 1 |
| ih | b it | b ih t 1 |
| iy | b eat | b iy t 1 |
| jh | jump | jh ah mp 1 |
| k | cat | k ae t 1 |
| l | lot | l aa t 1 |
| m | Mo m | m aa m 1 |
| n | nod | n aa d 1 |
| ng | si ng | s ih ng 1 |
| ow | b oat | b ow t1 |
| oy | b oy | b oy 1 |
| p | pot | p aa t 1 |
| r | rat | r ae t 1 |
| s | sit | s ih t 1 |
| sh | shut | sh ah t 1 |
| t | top | t aa p 1 |
| th | thick | th ih k 1 |
| uh | b ook | b uh k 1 |
| uw | b oot | b uw t 1 |
| v | vat | v ae t 1 |
| w | won | w ah n 1 |
| y | you | y uw 1 |
| z | zoo | z uw 1 |
| zh | mea sure | m eh 1 zh er |
| 1 | Primary stress | |
| 2 | Secondary stress | |
| - | Syllable boundary | |
| & | word boundary | |
| ! | Sentence terminator | |
| , | Sentence terminator | |
| . | Sentence terminator | |
| ? | Sentence terminator | |
| _ | Silence |
On the Natural Voices bulletin boards, various people have discussed the theory behind the way Natural Voices generates speech. The engine operates at the "half-phoneme" level. Each phoneme is split into two pieces by the engine, and adjacent phonemes are evaluated to see which half-phonemes would generate the best speech, based on the engine's rules. This normally works well, but in some cases it produces incorrect pronunciations which can be nearly impossible to correct. Consider the Mike16 voice trying to pronounce the phrase "moonshine map". The word "moonshine" alone is pronounced correctly, but when you add the word "map" to the sentence, you get "myoonshine map". Normally you would just convert this into its phonetic equivalent of "m uw n 1 sh ay n 2 m ae p 1" and have it work, but the Mike16 Natural Voice will evaluate these phonemes, apply its rules, and continue to say "myoonshine map".
As one of the developers said in the Natural Voices discussion forum, "You can suggest what you want from the engine, but [there is] no guarantee you will get it. There are ways to control it, but it's not always possible to get exactly what you want."
Additionally, not all of the US English Natural voices will generate the same pronunciation from a given hint. The Crystal16 voice has no problem with "moonshine map". This has the effect of making some pronunciation hints voice-specific.
| Previous | Next | Contents |